La matriz de confusión y sus métricas

La Matriz de confusión
En el campo de la inteligencia artificial y el aprendizaje automático una matriz de confusión es una herramienta que permite visualizar el desempeño de un algoritmo de aprendizaje supervisado. Cada columna de la matriz representa el número de predicciones de cada clase, mientras que cada fila representa a las instancias en la clase real., o sea en términos prácticos nos permite ver qué tipos de aciertos y errores está teniendo nuestro modelo a la hora de pasar por el proceso de aprendizaje con los datos.
Veamos esto con un ejemplo práctico de nuestra realidad actual :
Pensemos en un algoritmo que nos permite clasificar pacientes covid19 en positivos y negativos:
En este ejemplo tenemos un grupo de 100 pacientes de los cuales hay 45 que si tienen el virus y 55 que no lo tienen.
Nuestro algoritmo supervisado de clasificación entre otras cosas, nos va a ayudar a determinar cual es el % de acierto de nuestras pruebas.
Realizamos las pruebas respectivas a los pacientes y de ésta forma, podríamos comparar los resultados del modelo real contra el modelo predictivo:
Las 4 opciones siguientes son las que conforman lo que se conoce como la matriz de confusión:
( en este caso al ser sólo dos posibilidades: positivo o negativo (o clase 1 y clase 2]), hablamos de una matriz binaria. Aca entonces surgen cuatro opciones:
- ) Persona que tiene covid19 y el modelo lo clasificó como covid19 (+) . Esto sería un verdadero positivo o VP .
- ) Persona que no tiene covid19 y el modelo lo clasifico como covid19 (-) . Este seria un verdadero negativo o sea un VN.
- ) Persona que tiene covid19 y el modelo lo clasificó como covid19 (-) . Éste seria un error tipo II o un falso negativo o FN.
- ) Persona que no tiene covid19 y el modelo lo clasificó como covid19 (+) . Este es un error tipo I, o un falso positivo o FP.
Ahora de forma más clara, podemos identificar en nuestra matriz donde se ubican los errores ( las cajitas rojas)
La matriz de confusión como herramienta del aprendizaje automático
Imagine que tiene una prueba médica que verifica la presencia o ausencia de una enfermedad; en este caso si utilizáramos un algoritmo de aprendizaje automático basado en clasificación en este caso con variables categóricas, y par el cual usemos posiblemente un algoritmo de arboles decisorios) . De cualquier manera, en la vida real, hay dos posibles verdades : lo que se está probando es verdadero o no. La persona está enferma o no lo está; la imagen es un perro, o no lo es.
Debido a esto, también hay dos resultados de prueba posibles: un resultado de prueba positivo (la prueba predice que la persona está enferma o no, ó bien en el otro ejemplo la imagen es un perro, o no ). Estas 4 opciones se resumen en el siguiente cuadro , debido a que surgen dos posibles valores reales y dos posibles valores de predicción ó predictivos

MATRIZ DE CONFUSIÓN BINARIA
Esatas 4 opciones se conocen como la matriz de confusión. Veamos de nuevo esos 4 resultados posibles:
- Verdadero positivo: El valor real es positivo y la prueba predijo tambien que era positivo. O bien una persona está enferma y la prueba así lo demuestra.
- Verdadero negativo: El valor real es negativo y la prueba predijo tambien que el resultado era negativo. O bien la persona no está enferma y la prueba así lo demuestra.
- Falso negativo: El valor real es positivo, y la prueba predijo que el resultado es negativo. La persona está enferma, pero la prueba dice de manera incorrecta que no lo está. Esto es lo que en estadística se conoce como error tipo II
- Falso positivo: El valor real es negativo, y la prueba predijo que el resultado es positivo. La persona no está enferma, pero la prueba nos dice de manera incorrecta que silo está.
- Esto es lo que en estadística se conoce como error tipo I
A partir de estas 4 opciones surgen las métricas de la matriz de confusión : Por una parte la exactitud y la precisión y por otra la Sensibilidad y la Especificidad. Veámoslas en detalle:
a.) La Exactitud ( en inglés Accuracy ) y la Precisión (en inglés Precision)
a1.) La Exactitud
la Exactitud ( en inglés, “Accuracy”) se refiere a lo cerca que está el resultado de una medición del valor verdadero. En términos estadísticos, la exactitud está relacionada con el sesgo de una estimación. Se representa como la proporción de resultados verdaderos (tanto verdaderos positivos (VP) como verdaderos negativos (VN)) dividido entre el número total de casos examinados (verdaderos positivos, falsos positivos, verdaderos negativos, falsos negativos)
En forma práctica, la Exactitud es la cantidad de predicciones positivas que fueron correctas.
(VP+VN)/(VP+FP+FN+VN)
a2.) La Precisión
La Precisión (en inglés “Precision”) Se refiere a la dispersión del conjunto de valores obtenidos a partir de mediciones repetidas de una magnitud. Cuanto menor es la dispersión mayor la precisión. Se representa por la proporción de verdaderos positivos dividido entre todos los resultados positivos (tanto verdaderos positivos, como falsos positivos).
En forma práctica es el porcentaje de casos positivos detectados.
Se calcula como: VP/(VP+FP)
a3.) Sesgo (tambien llamado Bias, ó Inaccuracy):
Es la diferencia entre el valor medio y el verdadero valor de la magnitud medida. El sesgo pertenece al concepto de exactitud.
b.) La Sensibilidad (en Inglés Recall o sensitivity) y la Especificidad )( En inglés Especificity)
b1.) La Sensibilidad (“Recall” o “Sensitivity” ),
Se calcula así: : VP/(VP+FN), o lo que sería igual : Verdaderos positivos / Total Enfermos
b2.) La Especificidad (“Especificity”)
Se calcula: VN/(VN+FP),
Mediciones de la precisión de una prueba
Al calcular las relaciones entre estos valores, podemos medir cuantitativamente la precisión de nuestras pruebas.
La tasa de falsos positivos se calcula como FP / FP + TN, donde FP es el número de falsos positivos y TN es el número de verdaderos negativos (FP + TN es el número total de negativos). Es la probabilidad de que se produzca una falsa alarma: que se dé un resultado positivo cuando el valor verdadero sea negativo.
Hay muchas otras medidas posibles de precisión de la prueba y tasa de error. A continuación, se muestra un breve resumen de los más comunes:
1.) La tasa de falsos negativos, también llamada tasa de error, es la probabilidad de que la prueba pase por alto un verdadero positivo. Se calcula como FN / FN + VP, donde FN es el número de falsos negativos y VP es el número de verdaderos positivos
2.) La tasa de verdadero positivos (TVP, también llamada sensibilidad) se calcula como VP / VP + FN. La tasa de verdaderos positivos es la probabilidad de que un resultado positivo real dé positivo.
3.) La tasa de verdaderos negativos (también llamada especificidad), que es la probabilidad de que un resultado negativo real dé un resultado negativo. Se calcula como VN / VN + FP.
a.) El valor predictivo positivo es la probabilidad de que, si ha obtenido un resultado positivo en la prueba, realmente tenga la enfermedad. Se calcula como VP / VP + FP.
b.) El valor predictivo negativo, por el contrario es la probabilidad de que, si ha obtenido un resultado negativo en la prueba, en realidad no tenga la enfermedad.
Si colocamos todas las métricas en una solo gráfico obtenemos esto:

La matriz de confusión y sus métricas
EL F1 SCORE
Esta es otra métrica muy empleada porque nos resume la precisión y sensibilidad en una sola métrica. Por ello es de gran utilidad cuando la distribución de las clases es desigual, por ejemplo cuando el número de pacientes con una condición es del 15% y el otro es 85% , lo que en el campo de la salud es bastante común.
Se calcula:
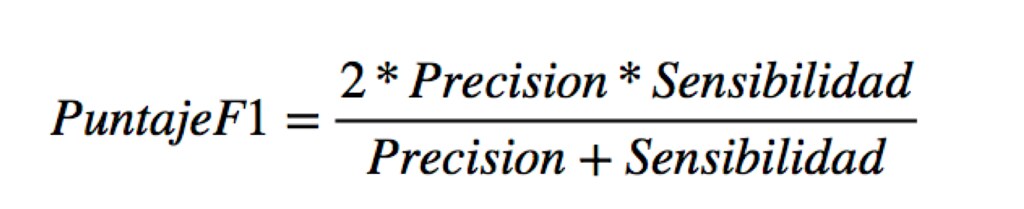
RESUMEN
Conforme a estas nuevas métricas podemos obtener cuatro casos posibles para cada clase:
- Alta precisión y alto recall: el modelo de Machine Learning escogido maneja perfectamente esa clase.
- Alta precisión y bajo recall: el modelo de Machine Learning escogido no detecta la clase muy bien, pero cuando lo hace es altamente confiable.
- Baja precisión y alto recall: El modelo de Machine Learning escogido detecta bien la clase, pero también incluye muestras de la otra clase.
- Baja precisión y bajo recall: El modelo de Machine Learning escogido no logra clasificar la clase correctamente.
Cuando tenemos un “dataset” con desequilibrio, suele ocurrir que obtenemos un alto valor de precisión en la clase Mayoritaria y un bajo recall en la clase Minoritaria. En el campo de la salud ésta circunstancia es particularmente frecuente y por ello tenemos que recurrir al balanceo de clases. Pueden ver el post sobre este tema en el siguiente enlace.
Ejemplo de la matriz de confusión real de una salida de un algoritmo de clasificación hecho con ayuda de una Jupyter Notebook y con set de datos de apenas con 80 pacientes: (con sólo fines educativos)

En los valores en el ejemplo ( el 4 y el 12) el 4 se refieren : a los falsos positivos de la clase 1, arriba a la derecha: , y el 13 a los falsos negativos de la clase 2, abajo izquierda:12)
Si sumamos 4 +12 / 80 (total falsos negativos + total falsos positivos ( o sea los errores ) y dividimos entre 80 ( que es el total de elementos del modelo) nos da un 20% que es el error global, y por tanto la precisión del modelo es la diferencia, o sea un 80 %
Ahora Veamos un ejemplo con todas las métricas asociadas a la matriz de confusión arriba descritas. En este caso hay 2 clases: la 1 y la 2 (prestar atención al valor del puntaje F1) f1-score

Si recordamos como se interpretan estas métricas:
- En la clase 2 por el contrario tenemos Alta precisión y bajo recall: por tanto nuestro modelo no detecta la clase muy bien, pero cuando lo hace es altamente confiable.
- En la clase 1 tenemos Baja precisión y alto recall, por lo tanto nuestro algoritmo detecta bien la clase, pero también incluye muestras de la otra clase.
el Score f1 es del 80%, lo que se considera apenas aceptable !
Consejos generales sobre La matriz de confusión y sus métricas :
1,) La precisión es un gran estadístico, Pero es útil únicamente cuando se tienen “datasets” simétricos (la cantidad de casos de la clase 1 y de las clase 2 tienen magnitudes similares)
2.) El indicador F1 de la matriz de confusión es útil si se tiene una distribución de clases desigual.
3.) Elija mayor precisión para conocer qué tan seguro está de los verdaderos positivos, Mientras que la sensibilidad o “Recall” le servirá para saber si no está perdiendo positivos.
4.) Las Falsas Alarmas .: Por ejemplo, si cree que es mejor en su caso tener falsos positivos que falsos negativos, utilice una sensibilidad alta (Recall) , cuando la aparición de falsos negativos le resulta inaceptable pero no le importa tener falsos positivos adicionales (falsas alarmas).
Un ejemplo de esto es: Prefieres que algunas personas sanas sean etiquetadas como diabéticas en lugar de dejar a una persona diabética etiquetada como sana.
5.) Elija precisión ( precision en inglés) si quiere estar más seguro de sus verdaderos positivos. por ejemplo, correos electrónicos no deseados. En este caso se prefiere tener algunos correos electrónicos “no deseados” en su bandeja de entrada en lugar de tener correos electrónicos “reales” en su bandeja de SPAM.
6.) Elija alta Especificidad: si desea identificar los verdaderos negativos, o lo que es igual cuando no desea falsos positivos. Por ejemplo conductores y las pruebas de alcoholemia
Un ejemplo de esto es: Se está llevando a cabo una prueba de drogas en la que todas las personas que dan positivo irán a la cárcel de inmediato, la idea es que ninguna persona “libre de drogas” vaya a la cárcel. Los falsos positivos aquí son intolerables.
——————————————————–
Este artículo fue escrito y adaptado de varias fuentes por el Dr. Juan Ignacio Barrios. MD MSc D Sc. El autor es médico y cirujano especialista en informática médica con una maestría en Business Intelligence y consultoría Tecnológica , es experto en BIG DATA y Ciencia de Datos. Aplica modelos de Machine Learning al campo de la salud . Actualmente reside en Barcelona donde es profesor visitante de la cátedra de Informática Médica de la Universidad de Barcelona. También es docente en Algoritmia, el Instituto Europeo de Formación Tecnológica.
Se han incluido tambien en este blog , algunos insumos muy valiosos de blogs de: Juan Ignacio Baignato, de Think Big , y Sarang Narkhede y del sitio split.io
Se agradece además a muchísimos lectores que con sus comentarios y mensajes de correo han contribuido a mejorar ésta publicación.
20 Responses
Muy completo, me ayudó mucho.
Gracias
Muy bueno, Gracias
Gracias, los explicaste mejor que mi maestra.
Gracias Daniel !!!
¡Muchas gracias! Qué genial la explicación.
Muchas gracias Alejandro !
Precisión debe ser: “Se representa por la proporción entre los positivos reales predichos por el algoritmo y todos los casos positivos.”
Exactitud debe ser : “Se representa por la proporción entre el número de predicciones correctas (tanto positivas como negativas) y el total de predicciones.”
Hola Lewis:
Es correcto. He cambiado la redacción para que se entienda mejor (La fórmula está correcta )
Exactitud: proporción de resultados verdaderos (tanto verdaderos positivos (VP) como verdaderos negativos (VN)) dividido entre el número total de casos examinados (verdaderos positivos, falsos positivos, verdaderos negativos, falsos negativos).
Precisión: proporción de verdaderos positivos dividido entre todos los resultados positivos (tanto verdaderos positivos, como falsos positivos).
Gracias por tus observaciones.
Juan
La fórmula de sensibilidad es incorrecta: VP/(VP+FP)
La fórmula de especificidad es incorrecta: VN/(VN+FN)
hola Lewis:
He verificado de nuevo las fórmulas y están correctas, debes verificarlo
Mira acá : https://www.fisterra.com/mbe/investiga/pruebas_diagnosticas/pruebas_diagnosticas.asp
tambien acá: https://www.sac.org.ar/cuestion-de-metodo/que-son-sensibilidad-y-especificidad/
Saludos y Gracias por visitar nuestra página
Juan
Excelente artículo!!!!. (Es solo para que no me bloqueen los comentarios)
Ya me percaté de que se necesita aprobación antes de… antes de aparecer. Sorry!!!. Espero se tengan en cuenta mis observaciones para su disertación.
Atte.
Científico de datos.
Hola, muy buena tu explicación. Quisiera saber de donde salen los valores de los falsos positivos y los falsos negativos (4 y 12). Es una estimación que uno mismo debe hacer?
Agradezco tu atención, saludos
Hola Luis: No esos valores salieron de aplicarle a los datos la herramienta de la matriz de confusión, como se observa en el post.
La sintaxis que debes usar en tu Jupyter Notebook es similar a esta
Primero debes importar las librerias necesarias:
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
luego aplicas la herramieta a los datos con un modelo X Y
predictions = model.predict(X)
print(confusion_matrix(y, predictions))
y obtienes un formato asi:
[18 13]
[16 33]
en este caso los falsos positivos y falsos negativos son: 13 y 16 ( ver diagrama de los cuadritos rojos y verdes)
Gracias por leer mis post
Una explicación bastante detallada y con ejemplos prácticos, ¡muchas gracias!
Muy completo y especifico muchas gracias.
Buenas tardes. ¡Excelente información! Tengo una duda, esperando me puedan orientar, por favor.
¿Cómo se puede aplicar una matriz de confusión a 3 datos de salida?
por supuesto lo mas común es la forma binaria pero puede ser a múltiples clases
Gracias por el material.